We are pleased to announce that O’Reilly’s Hadoop Application Architectures book is now available for early release! This early release contains the first 2 chapters of the book and can be found on O'Reilly's Catalog and on Safari.
The goal of this book is to provide developers and architects with guidance on architecting end-to-end solutions using Hadoop and tools in the Hadoop ecosystem. We have split the book into two broad sections - the first section discusses various considerations for designing applications, and the second section describes the architectures of some of the most commonly found applications of Hadoop and their architecture, thereby applying the considerations learned in the previous section.
In this early release, we are releasing the first two chapters from the first section of the book. In particular, these chapters concentrate on design considerations for Data Modeling and Data Movement in Hadoop.
Have you ever wondered:
* Whether your application should store data on Hadoop Distributed File System (HDFS) or HBase?
* If HDFS, what format should you store your data in? What compression codec should you use? What should your HDFS directories be called, which users should own them? What should be your partitioning columns? In general, what are the best practices for designing your HDFS schema?
* If HBase, how can you best design your HBase schema?
* What's the best way to store and access metadata in Hadoop? What kinds of metadata is there?
* What are the considerations for designing schema for SQL-on-Hadoop (e.g. Hive, Impala, HCatalog) tables?
In Chapter 1 - Data Modeling, we discuss considerations for above and many other questions to guide you with data modeling for your big data application . For example, one of the commonly asked questions about HDFS is the directory structure on HDFS. Below is a snippet from Chapter 1 discussing that topic:
/user/<username>: Data, jars and configuration files that belong only to a specific user. This is usually scratch type data that the user is currently experimenting with but is not part of a business process.
/etl: Data is in various stages of being processed by an ETL (extract, transform, and load) workflow.
/tmp: Temporary data generated by tools or shared between users. This directory is typically cleaned by an automated process and does not store long term data.
/data: Data sets that are shared across the organization. Since these are often critical data sources for analysis that drive business decisions, there are often controls around who can read and write this data. Very often user access is read only and data is written by automated (and audited) ETL processes
/app: Everything required for Hadoop applications to run, except data. This includes: jar files, Oozie workflow definitions, Hive HQL files, etc.
And, if you have wondered about:
* How much can the latency be before your data gets accessible to your end users? Few seconds, few minutes or few hours? How does the latency change the complexity of your design?
* What tools should you use for ingestion into your Hadoop cluster? File copy, Flume, Sqoop, Kafka, etc.? How do you decide which one to use?
* What tools should you use for egress of data out of your Hadoop cluster? File copy, Sqoop, etc.?
* Should you ingest or egress incrementally or overwrite it on every run?
* When using Flume, what kinds of sources, channels, sinks should you use?
* When using Sqoop, how do you choose a split-by column, and performance tune your sqoop import?
* When using Kafka, how do you integrate Kafka with Hadoop and the rest of its ecosystem?
Then, Chapter 2 - Data Movement is for you. For example, here is a design diagram we use in the book to desicribe high level design when using Camus (https://github.com/linkedin/camus), an open source project for ingesting data from Kafka to HDFS.
The goal of this book is to provide developers and architects with guidance on architecting end-to-end solutions using Hadoop and tools in the Hadoop ecosystem. We have split the book into two broad sections - the first section discusses various considerations for designing applications, and the second section describes the architectures of some of the most commonly found applications of Hadoop and their architecture, thereby applying the considerations learned in the previous section.
In this early release, we are releasing the first two chapters from the first section of the book. In particular, these chapters concentrate on design considerations for Data Modeling and Data Movement in Hadoop.
Have you ever wondered:
* Whether your application should store data on Hadoop Distributed File System (HDFS) or HBase?
* If HDFS, what format should you store your data in? What compression codec should you use? What should your HDFS directories be called, which users should own them? What should be your partitioning columns? In general, what are the best practices for designing your HDFS schema?
* If HBase, how can you best design your HBase schema?
* What's the best way to store and access metadata in Hadoop? What kinds of metadata is there?
* What are the considerations for designing schema for SQL-on-Hadoop (e.g. Hive, Impala, HCatalog) tables?
In Chapter 1 - Data Modeling, we discuss considerations for above and many other questions to guide you with data modeling for your big data application . For example, one of the commonly asked questions about HDFS is the directory structure on HDFS. Below is a snippet from Chapter 1 discussing that topic:
/user/<username>: Data, jars and configuration files that belong only to a specific user. This is usually scratch type data that the user is currently experimenting with but is not part of a business process.
/etl: Data is in various stages of being processed by an ETL (extract, transform, and load) workflow.
/tmp: Temporary data generated by tools or shared between users. This directory is typically cleaned by an automated process and does not store long term data.
/data: Data sets that are shared across the organization. Since these are often critical data sources for analysis that drive business decisions, there are often controls around who can read and write this data. Very often user access is read only and data is written by automated (and audited) ETL processes
/app: Everything required for Hadoop applications to run, except data. This includes: jar files, Oozie workflow definitions, Hive HQL files, etc.
And, if you have wondered about:
* How much can the latency be before your data gets accessible to your end users? Few seconds, few minutes or few hours? How does the latency change the complexity of your design?
* What tools should you use for ingestion into your Hadoop cluster? File copy, Flume, Sqoop, Kafka, etc.? How do you decide which one to use?
* What tools should you use for egress of data out of your Hadoop cluster? File copy, Sqoop, etc.?
* Should you ingest or egress incrementally or overwrite it on every run?
* When using Flume, what kinds of sources, channels, sinks should you use?
* When using Sqoop, how do you choose a split-by column, and performance tune your sqoop import?
* When using Kafka, how do you integrate Kafka with Hadoop and the rest of its ecosystem?
Then, Chapter 2 - Data Movement is for you. For example, here is a design diagram we use in the book to desicribe high level design when using Camus (https://github.com/linkedin/camus), an open source project for ingesting data from Kafka to HDFS.
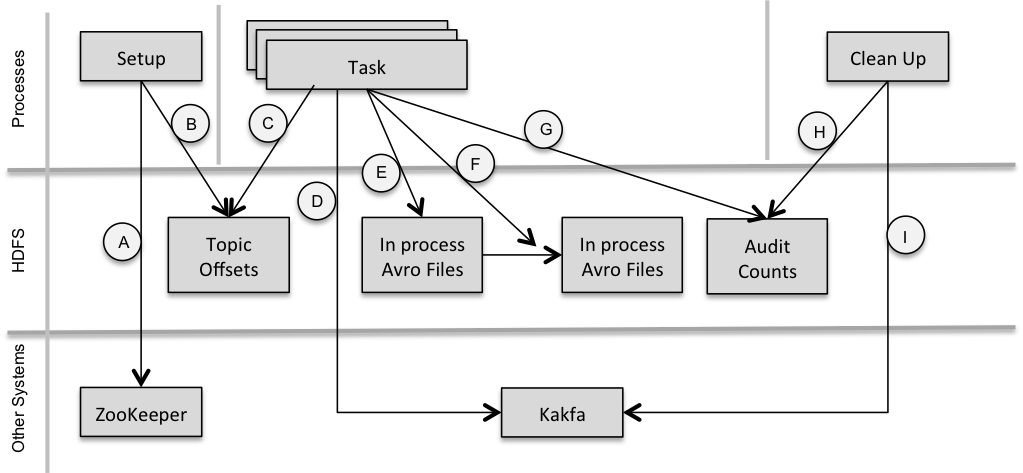
High level design with Camus
As you may have already noticed, the considerations and questions we discuss in this book are fairly broad questions, the answers to which rely heavily on understanding your application and its use-case. We provide you a very holistic set of considerations to think about and recommendations based on those considerations, when designing your big data application. However, we can't "recommend" a particular solution or product out of the box since that is strongly tied to your application. As pointed out earlier, we do share the architecture of commonly found applications of Hadoop and apply the discussed considerations and recommendations to those use-cases to explain their design.
Designing applications on Hadoop is hard and it shouldn’t be. This book is a step in that direction. We encourage you to check us out, get involved early and explore the answers to above questions with us. And, of course, we always value your feedback, both in terms of errata and improvements but also, hearing about topics that have you'd like to hear more of, from an application architecture perspective.
The work we have done so far wouldn't have been possible without the encouragement, support and reviews of many people. We thank all our reviewers so far, we will publish a comprehensive thank you list in the Acknowledgement section of the book.
And, we thank you for your continued interest in this book and hope to deliver (and keep you posted on) more design considerations and best practices in due course of time.
Happy Hadooping!
Hadoop Applications Architectures co-authors
Designing applications on Hadoop is hard and it shouldn’t be. This book is a step in that direction. We encourage you to check us out, get involved early and explore the answers to above questions with us. And, of course, we always value your feedback, both in terms of errata and improvements but also, hearing about topics that have you'd like to hear more of, from an application architecture perspective.
The work we have done so far wouldn't have been possible without the encouragement, support and reviews of many people. We thank all our reviewers so far, we will publish a comprehensive thank you list in the Acknowledgement section of the book.
And, we thank you for your continued interest in this book and hope to deliver (and keep you posted on) more design considerations and best practices in due course of time.
Happy Hadooping!
Hadoop Applications Architectures co-authors

